Add and/or Contribute a New Data Source
In case your data has not already been covered in the ecosystem, you can add it yourself which we try to make as easy as possible.
The first thing to consider is that you should produce a Pandas Dataframe. It should have one or two DateTime columns - 1 for an event, 2 for a period with a start and end date.
It is also useful to have a column called title. In any case, the Nostalgia DataFrame will infer the time and title columns automatically.
Following the pattern below will ensure that your data will play nicely with all the apps and query language.
Example
First install dependencies:
pip install psaw nostalgia
Now let's look at the code for collecting your self-written Reddit posts. It extends the basic Nostalgia DataFrame.
from nostalgia.times import datetime_from_timestamp from nostalgia.interfaces.post import PostInterface class RedditPosts(PostInterface): vendor = "reddit" @classmethod def ingest(cls, author): from psaw import PushshiftAPI api = PushshiftAPI() posts = [ { "title": x.title, "time": datetime_from_timestamp(x.created_utc), "url": x.full_link, "text": x.selftext, "author": author, } for x in api.search_submissions(author=author) ] cls.save_df(posts)
You can see that in this case it is only necessary to overwrite the ingest method.
In this case ingest takes an author as argument (e.g. "pvkooten") and will gather all the posts using the free (unauthenticated) PushShift API.
In it, you can see it makes use of the provided time helper function datetime_from_timestamp that will ensure it will be converted your current timezone from UTC. It calls nostalgia's save_df function which will compress and cache the data.
To load the data afterwards, it will use the basic load function of the NDF, which loads the cached and compressed data. Overwriting it will allow post-processing (not necessary in this example). It could be useful to for example add period itervals that cannot be represented by parquet files.
Here is the result after ingestion and loading using the timeline:
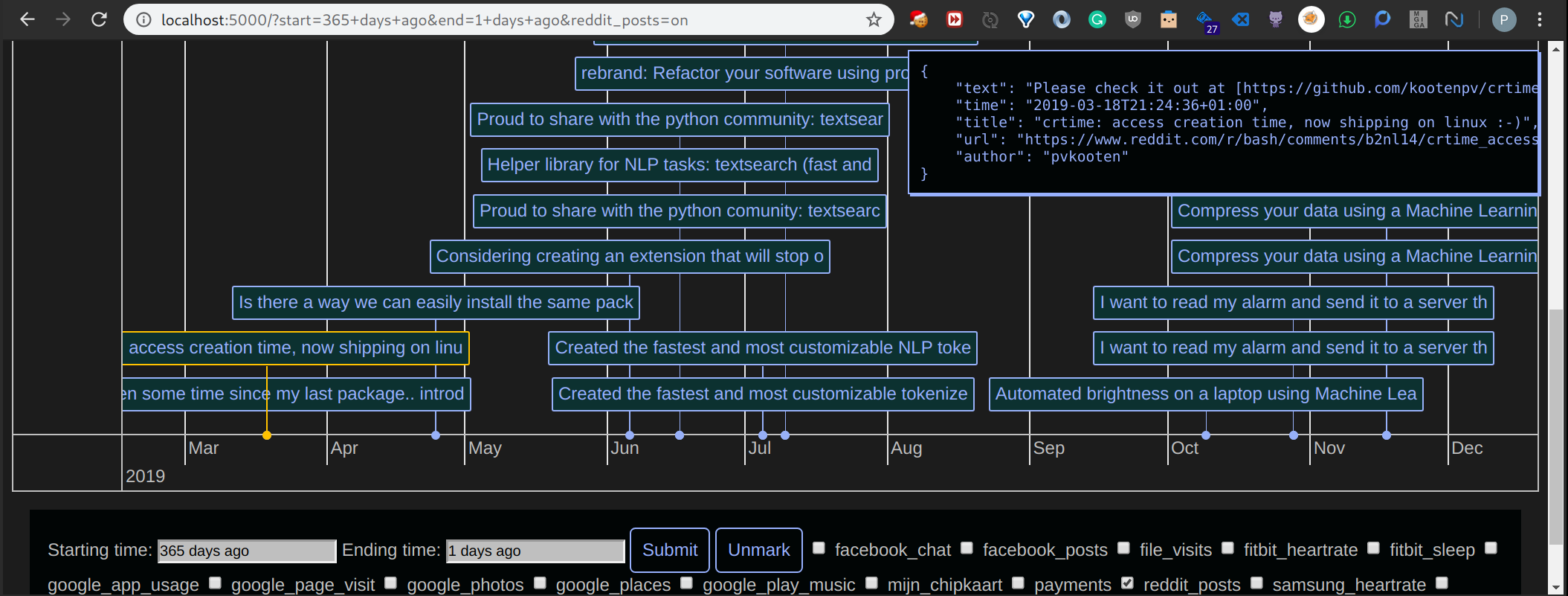
Details
Only when you need to make an API call or scrape data should you implement ingest. Otherwise you should only implement load.
Loading data
To do data ingestion, there are a few helper functions:
read_array_of_dict_from_json load_data_file_modified_time load_json_file_modified_time load_image_texts load_dataframe_per_json_file load_object_per_newline latest_file_is_historic
Basically the helper functions help with common file extensions such as CSV and JSON, and consider only having to process as little as possible.
For example, it will use modification time of a file to determine whether to do any processing.
See their docs for more info.
Time
There are a couple of time helper functions that can be used to get dates in the right timezone format:
Most notably for parsing:
datetime_from_timestamp: for parsing a integer or float representing the unix/epoch timestampdatetime_tz: create a normal datetime without providing a timezone and it will be localizeddatetime_from_format: takes a string and format without providing a timezone and it will be localizedparse_date_tz: takes a string and converts it to a timezone aware metadate object
These can be imported using e.g. from nostalgia.times import datetime_from_timestamp
Caching
It is recommended to use caching (to disk) for expensive calls, for e.g. long calculations, or API calls.
from nostalgia.cache import get_cache CACHE = get_cache("screenshots")
It depends on diskcache and is very useful. Data will be stored in ~/nostalgia_data/cache and can safely be removed, though at the obvious cost of having to recompute.